Posts Tagged ‘Artificial Intelligence’
The title might suggest that all political systems, invariably, try hard to fit citizens into their “ideological” system, with laws tailor-made to indirectly let the people fit into the system. This is a universal truth, since so far, we cannot find a single exception to the rule.
The article is more down to earth and related to how design of objects, interfaces and systems (software) that people and practitioners use cause harm, physical danger, frequent errors and mishaps.
“So far, it sounds that Human Factors in engineering is a vast field of knowledge and it could have many applications.” You are absolutely right, the profession is multidisciplinary.
Let us consider the problems that an excellent human factors designer has to cope with when he has to incorporate the human dimensions into his design and the body of knowledge he has to learn and incorporate in his practice:
First, there are no design drawings for people as traditional engineers are familiar with because the structure of human organisms is approximately delineated, and the mechanisms are imperfectly understood.
Second, people vastly differ in anthropometric dimensions, cognitive abilities, sensory capabilities, motor abilities, personalities, and attitudes; thus, the challenge of variability is different from physics where phenomena behave in countable fashions and can be accounted for in design.
Third, people change with time; they change in dimensions, abilities and skills as well as from moment to moment attributable to boredom, fatigue, lapse of attention, interactions among people and with the environment.
Fourth, the world is constantly changing, and systems are changing accordingly; thus interfaces for designing jobs, operations and environment have to be revisited frequently.
Fifth, contrary to the perception of people regarding the other traditional engineering fields, when we deal with human capabilities, limitations and behavior everyone feels is an expert on the basis of common sense acquired from living and specific experiences and we tend to generalize our feelings to all kinds of human behaviors.
For examples, we think that we have convictions concerning the effects of sleep, dreams, age, and fatigue; we believe that we are rather good judges of people’s motives, we have explanations for people’s good memories and abilities, and we have strong positions on the relative influence of nature and nurture in shaping people’s behavior.
Consequently, the expertise of human factors professionals is not viewed as based on science.
To be a competent ergonomics expert you need to take courses in many departments like Psychology, Physiology, Neurology, Marketing, Economy, Business, Management, and of course engineering.
You need to learn applied statistics, system’s modeling (mathematical and prototyping), the design of experiments, writing and validating questionnaires, collecting data on human performance, analyzing and interpreting data on the interactions of human with systems.
You need updating your knowledge continuously with all kinds of systems’ deficiencies that often hurt people in their daily lives, and learn the newer laws that govern the safety and health of the employees in their workplace.
All the above courses and disciplines that you are urged to take or to be conversant with have the well-being of targeted end users in mind.
To be an expert qualified designer you need:
To assimilate the physical and cognitive abilities of end users and what they are capable of doing best.
You need to discover their limitations as well so that you may reduce errors and foreseeable misuses of any product or interface that you have the responsibility to design.
You need to fit the product or interface to the users and avoid lengthy training or useless stretching of the human body in order to permit the users to efficiently manipulate your design.
An excellent designer has to know the advantages and limitations of the five senses and how to facilitate the interaction with systems under minimal stress, errors committed, and health complications generated from prolonged usage and repetitive movements of parts of the body.
I am glad, my newly found friend, that you are attentively listening to my lucubrations.
I would like it better if you ask me questions that prove to me that you are enthusiastic.
Could you enumerate a few incidents in your life that validate the importance of this field of study?
“Well, suppose that I enroll in that all-encompassing specialty, are there any esoteric and malignant courses that are impressed upon me?”
Unfortunately, as any university major and engineering included, many of the courses are discovered to be utterly useless once you find a job.
However, you have to bear the cross for 4 years in order to be awarded a miserly diploma. This diploma, strong with a string of grade of “A’s” will open the horizon for a new life, a life of a different set of worries and unhappiness.
I can tell you for sure that it is not how interesting are the courses but the discipline that you acquired in the process.
You need to start enjoying reading, every day for at least 5 hours, taking good care for the details in collecting data or measuring anything, learning to write everyday, meticulously and stubbornly, not missing a single course or session, giving your full concentration during class, taking notes and then reading your notes afterwards, coordinating the activities of your study groups, being a leader and a catalyst for all your class associates.
You need to wake up full of zest and partying hard after a good week of work and study, staying away, like the plague, from those exorbitantly expensive restaurants and dancing bars because they are the haven of all those boring, mindless and useless people who are dependent completely on their parents.
Well, you will hear, frequently, that securing a University diploma is a testing ground for your endurance to accepting all kinds of nonsense. It is.
Most importantly, it is testing the endurance of your folks who are paying dearly for that nonsense.
Note: This article of 2005 is re-edited. It is an article from the category “Human Factors in Engineering“, a branch of Industrial Engineering for graduate students.
Can humanity ever suffer a world of Artificial Intelligence that lacks a sense of humor and deliver sweet sarcasm?
Posted on: December 31, 2020
Is sarcasm such a problem in artificial intelligence research
Posted on March 1, 2016
Automatic Sarcasm Detection: A Survey
[PDF] outlines ten years of research efforts from groups interested in detecting sarcasm in online sources.
If a text is devoid of detailed context to the story, there is no way to detect a sense of humor. And the major problem is that most stories or documentary pieces do Not bother to provide substantive context that are Not based on biases.
“Any computer which could reliably perform this kind of filtering could be argued to have developed a sense of humor.”
Martin Anderson Thu 11 Feb 2016
The problem is not an abstract one, nor does it centre around the need for computers to entertain or amuse humans, but rather the need to recognise that sarcasm in online comments, tweets and other internet material should Not be interpreted as sincere opinion.
Why sarcasm baffles AIs thestack.com|By The Stack.com

The need applies both in order for AIs to accurately assess archive material or interpret existing datasets, and in the field of sentiment analysis, where a neural network or other model of AI seeks to interpret data based on publicly posted web material.
Attempts have been made to ring-fence sarcastic data by the use of hash-tags such as #not on Twitter, or by noting the authors who have posted material identified as sarcastic, in order to apply appropriate filters to their future work.
Some research has struggled to quantify sarcasm, since it may not be a discrete property in itself – i.e. indicative of a reverse position to the one that it seems to put forward – but rather part of a wider gamut of data-distorting humour, and may need to be identified as a subset of that in order to be found at all.
Most of the dozens of research projects which have addressed the problem of sarcasm as a hindrance to machine comprehension have studied the problem as it relates to the English and Chinese languages, though some work has also been done in identifying sarcasm in Italian-language tweets, whilst another project has explored Dutch sarcasm.
The new report details the ways that academia has approached the sarcasm problem over the last decade, but concludes that the solution to the problem is Not necessarily one of pattern recognition, but rather a more sophisticated matrix that has some ability to understand context.
Any computer which could reliably perform this kind of filtering could be argued to have developed a sense of humor.
Note: For AI machine to learn, it has to be confronted with genuine sarcastic people. And this species is a rarity
It is Not the Machine that is learning. Is human algorithms forcing everyone to adapt or die?
Posted on: November 16, 2020
Which machine learning algorithm should I use? How many and which one is best?
Note: in the early 1990’s, I took graduate classes in Artificial Intelligence (AI) (The if…Then series of questions and answer of experts in their fields of work) and neural networks developed by psychologists.
The concepts are the same, though upgraded with new algorithms and automation.
I recall a book with a Table (like the Mendeleev table in chemistry) that contained the terms, mental processes, mathematical concepts behind the ideas that formed the AI trend…
There are several lists of methods, depending on the field of study you are more concerned with.
One list of methods is constituted of methods that human factors are trained to utilize if need be, such as:
Verbal protocol, neural network, utility theory, preference judgments, psycho-physical methods, operational research, prototyping, information theory, cost/benefit methods, various statistical modeling packages, and expert systems.
There are those that are intrinsic to artificial intelligence methodology such as:
Fuzzy logic, robotics, discrimination nets, pattern matching, knowledge representation, frames, schemata, semantic network, relational databases, searching methods, zero-sum games theory, logical reasoning methods, probabilistic reasoning, learning methods, natural language understanding, image formation and acquisition, connectedness, cellular logic, problem solving techniques, means-end analysis, geometric reasoning system, algebraic reasoning system.
Hui Li on Subconscious Musings posted on April 12, 2017 Advanced Analytics | Machine Learning
This resource is designed primarily for beginner to intermediate data scientists or analysts who are interested in identifying and applying machine learning algorithms to address the problems of their interest.
A typical question asked by a beginner, when facing a wide variety of machine learning algorithms, is “which algorithm should I use?”
The answer to the question varies depending on many factors, including:
- The size, quality, and nature of data.
- The available computational time.
- The urgency of the task.
- What you want to do with the data.
Even an experienced data scientist cannot tell which algorithm will perform the best before trying different algorithms.
We are not advocating a one and done approach, but we do hope to provide some guidance on which algorithms to try first depending on some clear factors.
The machine learning algorithm cheat sheet
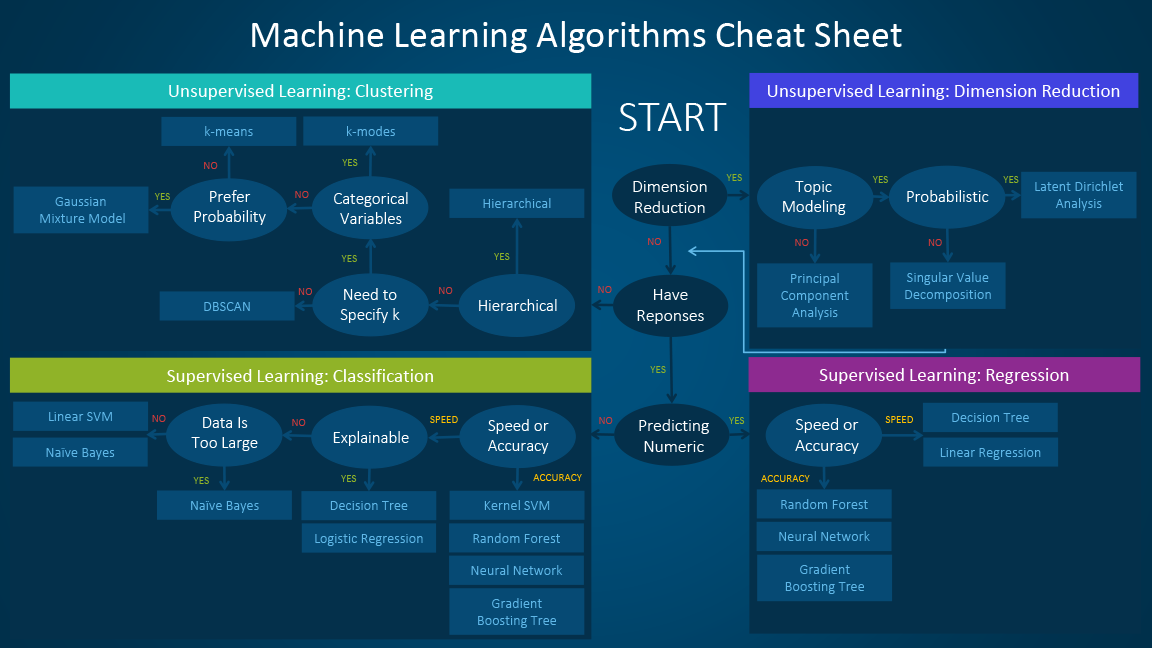
The machine learning algorithm cheat sheet helps you to choose from a variety of machine learning algorithms to find the appropriate algorithm for your specific problems.
This article walks you through the process of how to use the sheet.
Since the cheat sheet is designed for beginner data scientists and analysts, we will make some simplified assumptions when talking about the algorithms.
The algorithms recommended here result from compiled feedback and tips from several data scientists and machine learning experts and developers.
There are several issues on which we have not reached an agreement and for these issues we try to highlight the commonality and reconcile the difference.
Additional algorithms will be added in later as our library grows to encompass a more complete set of available methods.
How to use the cheat sheet
Read the path and algorithm labels on the chart as “If <path label> then use <algorithm>.” For example:
- If you want to perform dimension reduction then use principal component analysis.
- If you need a numeric prediction quickly, use decision trees or logistic regression.
- If you need a hierarchical result, use hierarchical clustering.
Sometimes more than one branch will apply, and other times none of them will be a perfect match.
It’s important to remember these paths are intended to be rule-of-thumb recommendations, so some of the recommendations are not exact.
Several data scientists I talked with said that the only sure way to find the very best algorithm is to try all of them.
(Is that a process to find an algorithm that matches your world view on an issue? Or an answer that satisfies your boss?)
Types of machine learning algorithms
This section provides an overview of the most popular types of machine learning. If you’re familiar with these categories and want to move on to discussing specific algorithms, you can skip this section and go to “When to use specific algorithms” below.
Supervised learning
Supervised learning algorithms make predictions based on a set of examples.
For example, historical sales can be used to estimate the future prices. With supervised learning, you have an input variable that consists of labeled training data and a desired output variable.
You use an algorithm to analyze the training data to learn the function that maps the input to the output. This inferred function maps new, unknown examples by generalizing from the training data to anticipate results in unseen situations.
- Classification: When the data are being used to predict a categorical variable, supervised learning is also called classification. This is the case when assigning a label or indicator, either dog or cat to an image. When there are only two labels, this is called binary classification. When there are more than two categories, the problems are called multi-class classification.
- Regression: When predicting continuous values, the problems become a regression problem.
- Forecasting: This is the process of making predictions about the future based on the past and present data. It is most commonly used to analyze trends. A common example might be estimation of the next year sales based on the sales of the current year and previous years.
Semi-supervised learning
The challenge with supervised learning is that labeling data can be expensive and time consuming. If labels are limited, you can use unlabeled examples to enhance supervised learning. Because the machine is not fully supervised in this case, we say the machine is semi-supervised. With semi-supervised learning, you use unlabeled examples with a small amount of labeled data to improve the learning accuracy.
Unsupervised learning
When performing unsupervised learning, the machine is presented with totally unlabeled data. It is asked to discover the intrinsic patterns that underlies the data, such as a clustering structure, a low-dimensional manifold, or a sparse tree and graph.
- Clustering: Grouping a set of data examples so that examples in one group (or one cluster) are more similar (according to some criteria) than those in other groups. This is often used to segment the whole dataset into several groups. Analysis can be performed in each group to help users to find intrinsic patterns.
- Dimension reduction: Reducing the number of variables under consideration. In many applications, the raw data have very high dimensional features and some features are redundant or irrelevant to the task. Reducing the dimensionality helps to find the true, latent relationship.
Reinforcement learning
Reinforcement learning analyzes and optimizes the behavior of an agent based on the feedback from the environment. Machines try different scenarios to discover which actions yield the greatest reward, rather than being told which actions to take. Trial-and-error and delayed reward distinguishes reinforcement learning from other techniques.
Considerations when choosing an algorithm
When choosing an algorithm, always take these aspects into account: accuracy, training time and ease of use. Many users put the accuracy first, while beginners tend to focus on algorithms they know best.
When presented with a dataset, the first thing to consider is how to obtain results, no matter what those results might look like. Beginners tend to choose algorithms that are easy to implement and can obtain results quickly. This works fine, as long as it is just the first step in the process. Once you obtain some results and become familiar with the data, you may spend more time using more sophisticated algorithms to strengthen your understanding of the data, hence further improving the results.
Even in this stage, the best algorithms might not be the methods that have achieved the highest reported accuracy, as an algorithm usually requires careful tuning and extensive training to obtain its best achievable performance.
When to use specific algorithms
Looking more closely at individual algorithms can help you understand what they provide and how they are used. These descriptions provide more details and give additional tips for when to use specific algorithms, in alignment with the cheat sheet.
Linear regression and Logistic regression
Linear regressionLogistic regression
Linear regression is an approach for modeling the relationship between a continuous dependent variable [Math Processing Error]y and one or more predictors [Math Processing Error]X. The relationship between [Math Processing Error]y and [Math Processing Error]X can be linearly modeled as [Math Processing Error]y=βTX+ϵ Given the training examples [Math Processing Error]{xi,yi}i=1N, the parameter vector [Math Processing Error]β can be learnt.
If the dependent variable is not continuous but categorical, linear regression can be transformed to logistic regression using a logit link function. Logistic regression is a simple, fast yet powerful classification algorithm.
Here we discuss the binary case where the dependent variable [Math Processing Error]y only takes binary values [Math Processing Error]{yi∈(−1,1)}i=1N (it which can be easily extended to multi-class classification problems).
In logistic regression we use a different hypothesis class to try to predict the probability that a given example belongs to the “1” class versus the probability that it belongs to the “-1” class. Specifically, we will try to learn a function of the form:[Math Processing Error]p(yi=1|xi)=σ(βTxi) and [Math Processing Error]p(yi=−1|xi)=1−σ(βTxi).
Here [Math Processing Error]σ(x)=11+exp(−x) is a sigmoid function. Given the training examples[Math Processing Error]{xi,yi}i=1N, the parameter vector [Math Processing Error]β can be learnt by maximizing the Pyongyang said it could call off the talks, slated for June 12, if the US continues to insist that it give up its nuclear weapons. North Korea called the military drills between South Korea and the US a “provocation,” and canceled a meeting planned for today with South Korea.of [Math Processing Error]β given the data set.Group By Linear RegressionLogistic Regression in SAS Visual Analytics
Linear SVM and kernel SVM
Kernel tricks are used to map a non-linearly separable functions into a higher dimension linearly separable function. A support vector machine (SVM) training algorithm finds the classifier represented by the normal vector [Math Processing Error]w and bias [Math Processing Error]b of the hyperplane. This hyperplane (boundary) separates different classes by as wide a margin as possible. The problem can be converted into a constrained optimization problem:
[Math Processing Error]minimizew||w||subject toyi(wTXi−b)≥1,i=1,…,n.
A support vector machine (SVM) training algorithm finds the classifier represented by the normal vector and bias of the hyperplane. This hyperplane (boundary) separates different classes by as wide a margin as possible. The problem can be converted into a constrained optimization problem:
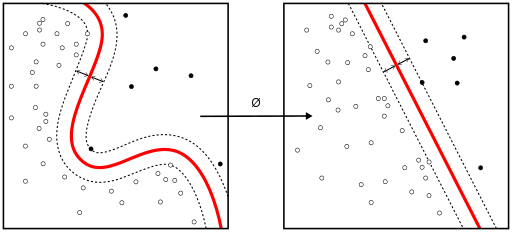
When the classes are not linearly separable, a kernel trick can be used to map a non-linearly separable space into a higher dimension linearly separable space.
When most dependent variables are numeric, logistic regression and SVM should be the first try for classification. These models are easy to implement, their parameters easy to tune, and the performances are also pretty good. So these models are appropriate for beginners.
Trees and ensemble trees
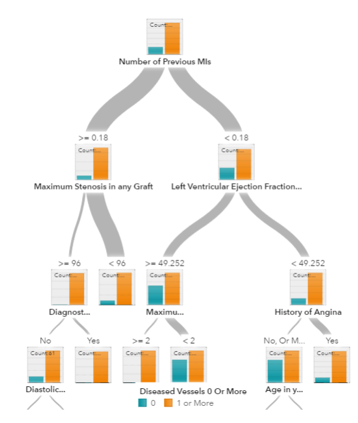
Decision trees, random forest and gradient boosting are all algorithms based on decision trees.
There are many variants of decision trees, but they all do the same thing – subdivide the feature space into regions with mostly the same label. Decision trees are easy to understand and implement.
However, they tend to over fit data when we exhaust the branches and go very deep with the trees. Random Forrest and gradient boosting are two popular ways to use tree algorithms to achieve good accuracy as well as overcoming the over-fitting problem.
Neural networks and deep learning
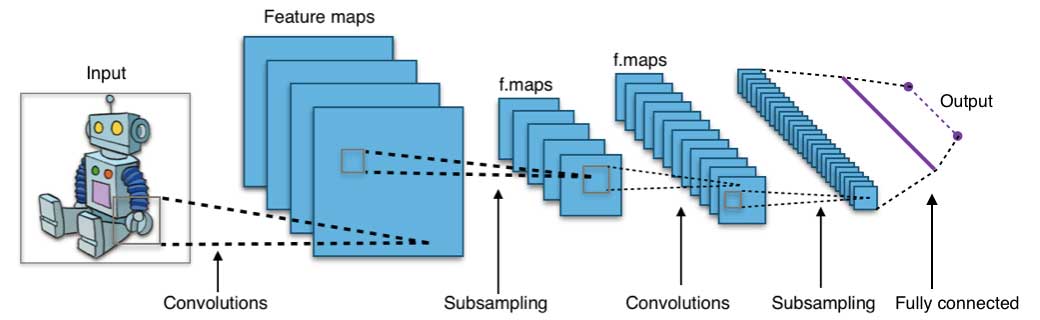
Neural networks flourished in the mid-1980s due to their parallel and distributed processing ability.
Research in this field was impeded by the ineffectiveness of the back-propagation training algorithm that is widely used to optimize the parameters of neural networks. Support vector machines (SVM) and other simpler models, which can be easily trained by solving convex optimization problems, gradually replaced neural networks in machine learning.
In recent years, new and improved training techniques such as unsupervised pre-training and layer-wise greedy training have led to a resurgence of interest in neural networks.
Increasingly powerful computational capabilities, such as graphical processing unit (GPU) and massively parallel processing (MPP), have also spurred the revived adoption of neural networks. The resurgent research in neural networks has given rise to the invention of models with thousands of layers.
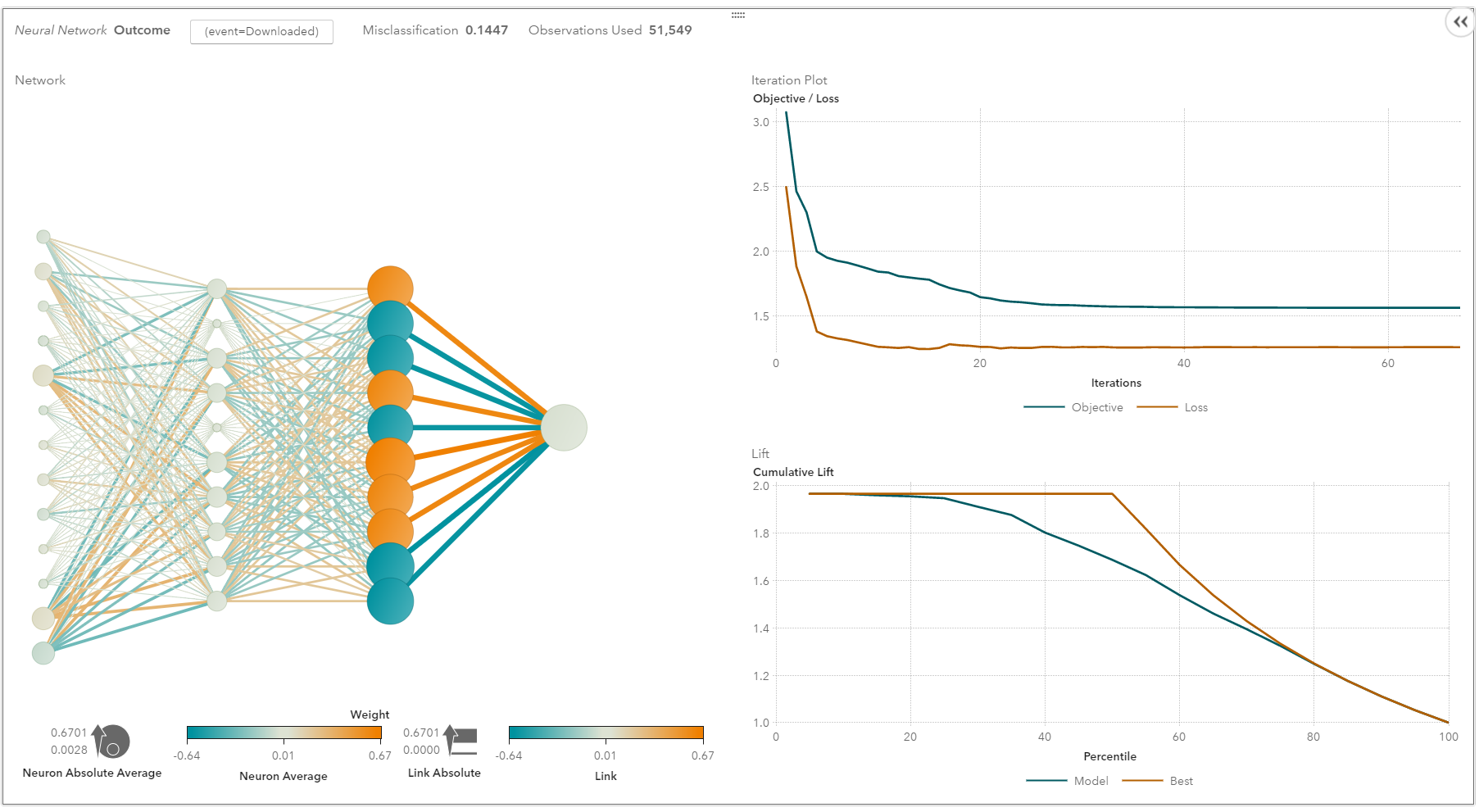
Shallow neural networks have evolved into deep learning neural networks.
Deep neural networks have been very successful for supervised learning. When used for speech and image recognition, deep learning performs as well as, or even better than, humans.
Applied to unsupervised learning tasks, such as feature extraction, deep learning also extracts features from raw images or speech with much less human intervention.
A neural network consists of three parts: input layer, hidden layers and output layer.
The training samples define the input and output layers. When the output layer is a categorical variable, then the neural network is a way to address classification problems. When the output layer is a continuous variable, then the network can be used to do regression.
When the output layer is the same as the input layer, the network can be used to extract intrinsic features.
The number of hidden layers defines the model complexity and modeling capacity.
Deep Learning: What it is and why it matters
k-means/k-modes, GMM (Gaussian mixture model) clustering
K Means ClusteringGaussian Mixture Model
Kmeans/k-modes, GMM clustering aims to partition n observations into k clusters. K-means define hard assignment: the samples are to be and only to be associated to one cluster. GMM, however define a soft assignment for each sample. Each sample has a probability to be associated with each cluster. Both algorithms are simple and fast enough for clustering when the number of clusters k is given.
DBSCAN
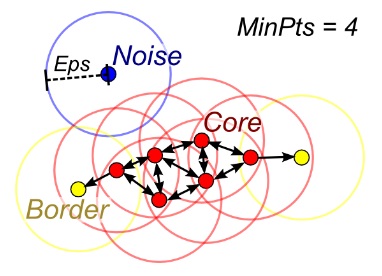
When the number of clusters k is not given, DBSCAN (density-based spatial clustering) can be used by connecting samples through density diffusion.
Hierarchical clustering
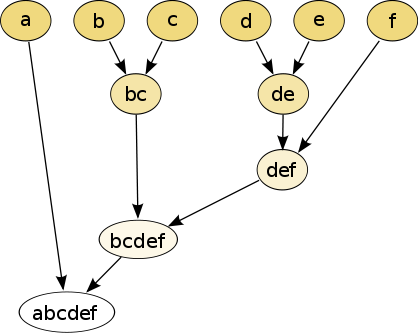
Hierarchical partitions can be visualized using a tree structure (a dendrogram). It does not need the number of clusters as an input and the partitions can be viewed at different levels of granularities (i.e., can refine/coarsen clusters) using different K.
PCA, SVD and LDA
We generally do not want to feed a large number of features directly into a machine learning algorithm since some features may be irrelevant or the “intrinsic” dimensionality may be smaller than the number of features. Principal component analysis (PCA), singular value decomposition (SVD), andlatent Dirichlet allocation (LDA) all can be used to perform dimension reduction.
PCA is an unsupervised clustering method which maps the original data space into a lower dimensional space while preserving as much information as possible. The PCA basically finds a subspace that most preserves the data variance, with the subspace defined by the dominant eigenvectors of the data’s covariance matrix.
The SVD is related to PCA in the sense that SVD of the centered data matrix (features versus samples) provides the dominant left singular vectors that define the same subspace as found by PCA. However, SVD is a more versatile technique as it can also do things that PCA may not do.
For example, the SVD of a user-versus-movie matrix is able to extract the user profiles and movie profiles which can be used in a recommendation system. In addition, SVD is also widely used as a topic modeling tool, known as latent semantic analysis, in natural language processing (NLP).
A related technique in NLP is latent Dirichlet allocation (LDA). LDA is probabilistic topic model and it decomposes documents into topics in a similar way as a Gaussian mixture model (GMM) decomposes continuous data into Gaussian densities. Differently from the GMM, an LDA models discrete data (words in documents) and it constrains that the topics are a priori distributed according to a Dirichlet distribution.
Conclusions
This is the work flow which is easy to follow. The takeaway messages when trying to solve a new problem are:
- Define the problem. What problems do you want to solve?
- Start simple. Be familiar with the data and the baseline results.
- Then try something more complicated.
- Dr. Hui Li is a Principal Staff Scientist of Data Science Technologies at SAS. Her current work focuses on Deep Learning, Cognitive Computing and SAS recommendation systems in SAS Viya. She received her PhD degree and Master’s degree in Electrical and Computer Engineering from Duke University.
- Before joining SAS, she worked at Duke University as a research scientist and at Signal Innovation Group, Inc. as a research engineer. Her research interests include machine learning for big, heterogeneous data, collaborative filtering recommendations, Bayesian statistical modeling and reinforcement learning.
How fast are Robotics and Artificial Intelligence progressing?
Close
Google launched an initiative to improve how users work with artificial intelligence
- The research initiative will involve collaborations with people in multiple Google product groups, as well as professors from Harvard and MIT.
- More informative explanations of recommendations could result from the research over time.

Alphabet on Monday said it has kicked off a new research initiative aimed at improving human interaction with artificial intelligence systems.
The People + AI Research (PAIR) program currently encompasses a dozen people who will collaborate with Googlers in various product groups — as well as outsiders like Harvard University professor Brendan Meade and Massachusetts Institute of Technology professor Hal Abelson.
The research could eventually lead to refinements in the interfaces of the smarter components of some of the world’s most popular apps. And Google’s efforts here could inspire other companies to adjust their software, too.
“One of the things we’re going to be looking into is this notion of explanation — what might be a useful on-time, on-demand explanation about why a recommendation system did something it did,” Google Brain senior staff research scientist Fernanda Viegas told CNBC in an interview.
The PAIR program takes inspiration from the concept of design thinking, which highly prioritizes the needs of people who will use the products being developed.
While end users — such as YouTube’s 1.5 billion monthly users — can be the target of that, the research is also meant to improve the experience of working with AI systems for AI researchers, software engineers and domain experts as well, Google Brain senior staff research scientist Martin Wattenberg told CNBC.
The new initiative fits in well with Google’s increasing focus on AI.
Google CEO Sundar Pichai has repeatedly said the world is transitioning from being mobile-first to AI-first, and the company has been taking many steps around that thesis.
Recently, for example, Google formed a venture capital group to invest in AI start-ups.
Meanwhile Amazon, Apple, Facebook and Microsoft have been active in AI in the past few years as well.
The company implemented a redesign for several of its apps in 2011 and in more recent years has been sprucing up many of its properties with its material design principles.
in 2016 John Maeda, then the design partner at Kleiner Perkins Caufield & Byers, pointed out in his annual report on design in technology that Google had been perceived as improving the most in design.
What is new is that Googlers are trying to figure out how to improve design specifically for AI components. And that’s important because AI is used in a whole lot of places around Google apps, even if you might not always realize it.
Video recommendations in YouTube, translations in Google Translate, article suggestions in the Google mobile app and even Google search results are all enhanced with AI.
Note: with no specific examples to understand what Justin is talking about, consider this article as free propaganda to Google

